![]()
![]()
![]()
![]()
Prof. Dr.-Ing. Alfred Ludwig
The goal of the INF project is to enable and achieve data-driven knowledge-discovery out of the CRC data beyond the current capabilities, using adapted research data management and artificial intelligence (AI) tools such as machine learning algorithms. To be able to achieve this goal, the INF project will organize the heterogenous mass of different data in the CRC systematically and provide the researchers in the CRC with the required infrastructure and tools for creating consistent, high-quality, re-useable datasets in accordance with the FAIR principles. INF will enable efficient research data management (RDM) and will provide guidance and support for making best use of research data.
A key to building valid and valuable datasets which are suitable for AI-driven knowledge discovery is a strong and well-organized RDM concept which involves intensive and regular communication between all CRC scientists in order to achieve a high acceptance level of RDM and the resulting FAIR use of data and metadata from the different CRC projects. This communication will be supported through explanatory metadata schemes and through direct interaction with the scientists that generate the data. Understanding the data-generating procedures in detail is important to collect relevant information. Therefore, the INF project relies on strong communication & interaction with the individual projects.
This is based on the experience that it is not enough to offer a RDM system and hope that it is useful, self-explaining and self-evident. Rather, it takes huge efforts to convince researchers to use these new possibilities to their favour. From our experience, established approaches of continuously collecting data and metadata in electronic laboratory notebooks (ELN) frequently fail due to lack of user compliance or motivation. This frequently leads to a heterogenous collection of individual data for which reusability requires huge efforts downstream by analysing the data, processing the data, sorting outliers and building a dataset for an individual statistics or machine learning study.
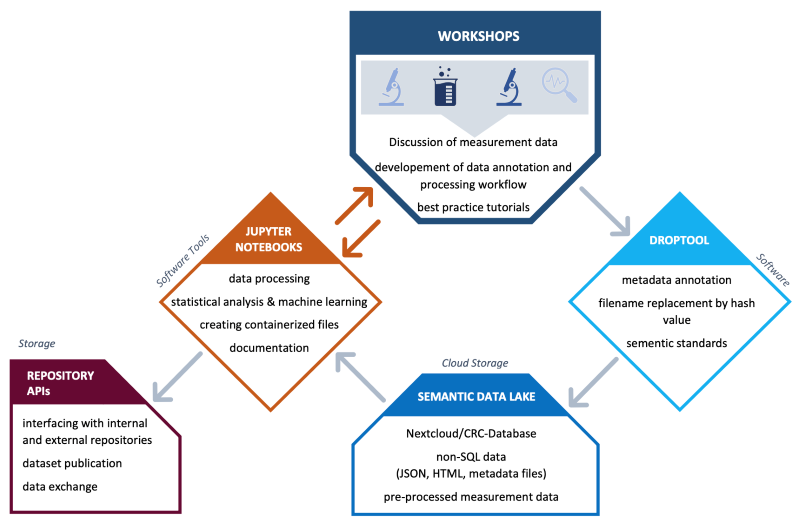
Therefore, the INF project aims to employ a new strategy for building a CRC community dataset, analysis software and predictive AI models. Rather than building a large, complicated RDM system or ELN, we envision a more flexible approach by building task-centered datasets for the development and application of AI-methods for analysis and prediction. As many projects already have a working data infrastructure, additional workload associated with CRC-related data annotation and processing should be minimized. Inspired by the agile software development framework SCRUM, datasets will instead be developed in data sprints, i.e., workshops that evolve around certain facets of the research activities in the CRC. The goal is to motivate all scientists in the projects to actively participate in dataset building and generating scientific publications centered around the evaluation of larger datasets or the development of advanced AI analysis tools, using the CRC datasets and the provided AI-tools. The INF scientist (“data manager”) will provide support and guidance for this endeavour. The generated datasets and code (e.g., in form of custom-built Jupyter notebooks for machine learning with CRC data) will follow the FAIR principles and guidelines from broader initiatives such as MaterialDigital, NDFI4chem, NFDI4MatWerk and NFDI4cat.
(Figure: Illustration of the CRC’s RDM concept in the second funding period).

Copyright © TRR247 2023
Last update: Jun 29, 2023